- R1-Zero: trained with large-scale RL without supervised fine-tuning (SFT)
DeepSeek R1-Zero
R1-Zero naturally learns to solve increasingly complex reasoning tasks by leveraging extended test-time computation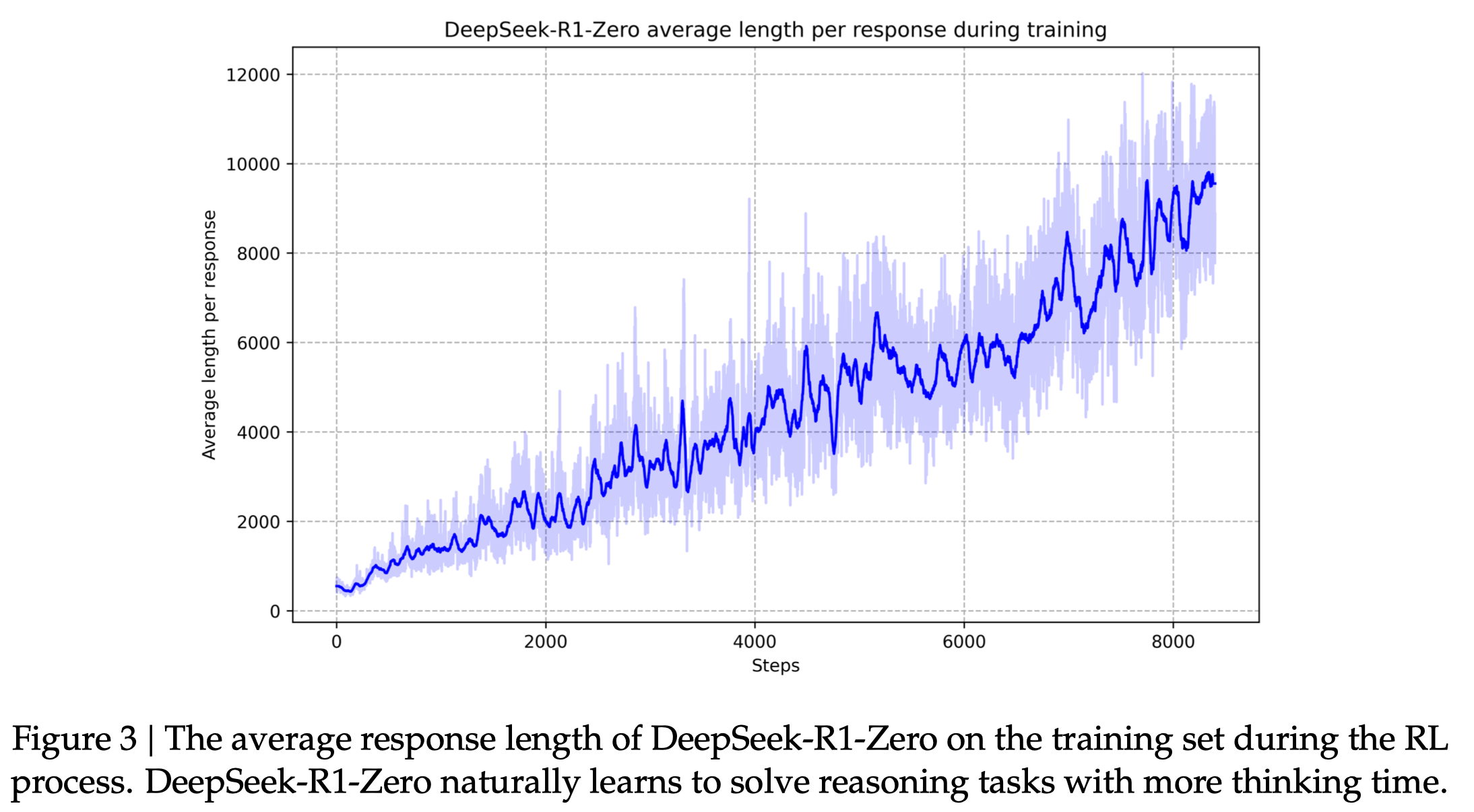
Emergence of sophisticated behaviors as the test-time computation increases
- reflection: revisits and reevaluates previous steps
- exploration of alternative approaches
Reward: rule-based reward system
- accuracy rewards
- math problems with deterministic results
- LeetCode problems with predefined test cases that can be tested by a compiler
- format rewards
- reasoning process and answer should be enclosed within <think> </think> and <answer> </answer> tags, respectively,
Drawbacks: struggles with challenges like poor readability, and language mixing
DeepSeek-R1: RL with Cold Start
- : improve performance / accelerate convergence by incorporating a small amount of high-quality data as a cold start
- Cold start
- collect thousands of long CoT data to fine-tune the model as initial RL actor
- data collection:
- few-shot prompting with a long CoT as an example,
- directly prompting models to generate model detailed answers with reflection and verification
- gathering R1-Zero outputs in a readable format and post-processing by human annotators
- benefit: readability and better performance
- Reasoning-oriented RL
- train by reasoning-intensive tasks such as coding, mathematics, science, and logic reasoning, which involve well-defined problems with clear solutions
- language consistency reward
- Rejection Sampling and Supervised Fine-Tuning
- check stage 2’s RL converges, use the checkpointing model to collect SFT data
- reasoning data
- non-reasoning data
- RL for all Scenarios
- a secondary RL stage aiming at helpfulness and harmlessness (alignment?)
Unsuccessful Attempts
- Process Reward Model (PRM)
- Monte Carlo Tree Search (MCTS)
Distillation
- Distillation
- Using the reasoning data generated by DeepSeek-R1, we fine-tuned several dense models that are widely used in the research community.
- Distillation vs. RL
- distillation: economical and effective but cannot advance beyond the boundaries
- OpenAI o1: first to introduce inference-time scaling
- increase the length of CoT