- Based on how they interact together
- RL4LLM
- : use RL to improve the performance of LLMs
- fine-tune existing LLM
- improve prompt
- LLM4RL
- : use LLM to improve an RL model that is inherently not related to natural language
- further classification on where LLM is taking effects:
- reward shaping,
- goal generation,
- policy function
- utilize 3 abilities of LLM:
- zero-shot / few-shot learning ability
- real-world knowledge: help with exploration
- reasoning capabilities
- RL+LLM
- : work together in a common planning framework
- without either of them contributing to training or fine-tuning of the other
- further: w/ vs. wo/ natural language feedback
- : work together in a common planning framework
- RL4LLM
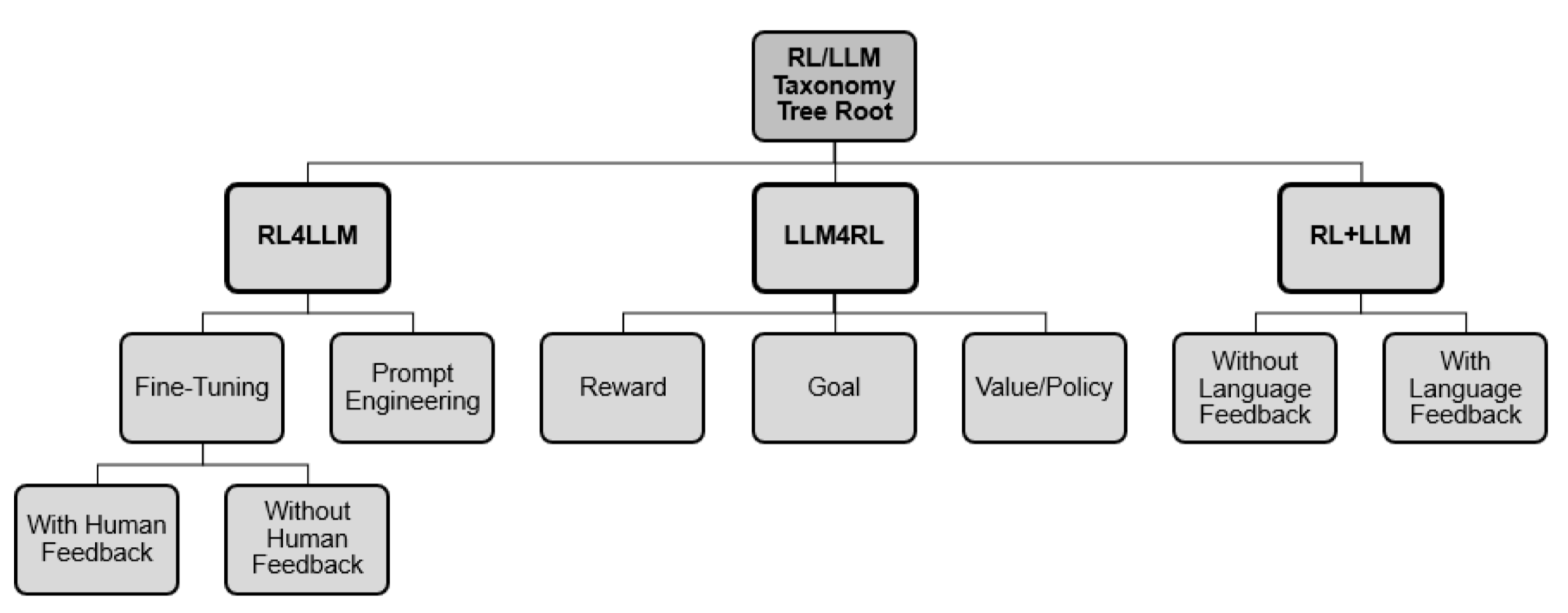
RL4LLM-Fine-tuning: eg RL tweaks model’s parameters
RL4LLM-Prompt Engineering: RL iteratively update the prompt
LLM4RL-Reward Shaping: LLM design the reward function of the RL agent
LLM4RL-Goal Generation: LLM is utilized for goal setting, applying to goal-conditioned RL
LLM4RL-Policy: LLM represents the policy function of the RL agent
RL+LLM-No Language Feedback
RL+LLM-Language Feedback
LLM’s training is already involved with RL in the form of RLHF. This paper is concerned with RL with already trained LLMs.
Q:
- what is the SOTA representative in each category?
Links
- RL